Linked大佬Jay Kreps曾发表过一篇博客,简单阐述了他对数据仓库架构设计的一些想法。从Lambda架构的缺点到提出基于实时数据流的Kappa架构。本文将在Kappa架构基础上,进一步谈数仓架构设计。
什么是Lambda架构?
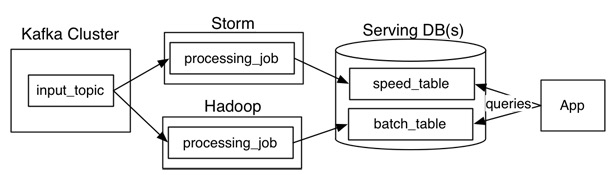
借用Jay Kreps的一张图来看,Lambda架构主要由这几部分构成:数据源(Kafka),数据处理(Storm,Hadoop),服务数据库(Serving DB)。其中数据源和服务数据库是整个架构数据的入口和出口。数据处理则是分为在在线处理和离线处理两部分。
当数据通过kafka消息中间件,进入Lambda架构后,会同时进入离线处理(Hadoop)和实时处理(Storm)两个处理模块。离线处理进行批计算,将大量T+1的数据进行汇总。而实时处理则是进行流处理或者是微批处理,计算秒级、分钟级的结果。最后都录入到服务数据库(Serving DB)中进行汇总,暴露给上层服务调用。
Lambda架构的好处是:架构简单,很好的结合了离线批处理和实时流处理的优点,稳定且实时计算成本可控。
此外,它对数据订正也很友好。如果后期数据统计口径变更,重新运行离线任务,则可以很快的将历史数据订正为最新的口径。
然而,Lambda也有很多问题。
其中Jay Kreps认为最突出的问题就是需要同时维护实时处理和离线处理两套代码的同时还要保证两套处理结果保持一致。这无疑是非常让人头疼的。
什么是Kappa架构
Jay Kreps认为通过非常,非常快地增加并行度和重播历史来处理重新处理实时数据,避免在实时数据处理系统上再“粘粘”一个离线数据处理系统。于是,他提出了这样的架构:
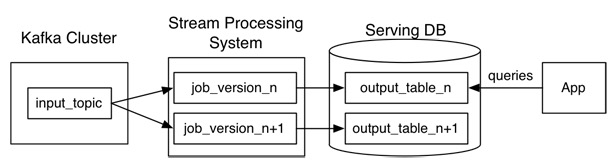
Kafka或者其他消息中间件,具备保留多日数据的能力。正常情况下kafka都是吐出实时数据,经过实时处理系统,进入服务数据库(Serving DB)。
当系统需要数据订正时,重放消息,修正实时处理代码,扩展实时处理系统的并发度,快速回溯过去历史数据。
这样的架构简单,避免了维护两套系统还需要保持结果一致的问题,也很好解决了数据订正问题。
但它也有它的问题:
1、消息中间件缓存的数据量和回溯数据有性能瓶颈。通常算法需要过去180天的数据,如果都存在消息中间件,无疑有非常大的压力。同时,一次性回溯订正180天级别的数据,对实时计算的资源消耗也非常大。
2、在实时数据处理时,遇到大量不同的实时流进行关联时,非常依赖实时计算系统的能力,很可能因为数据流先后顺序问题,导致数据丢失。
例如:一个消费者在淘宝网上搜索商品。正常来说,搜索结果里,商品曝光数据应该早于用户点击数据产出。然而因为可能会因为系统延迟,导致相同商品的曝光数据晚于点击数据进入实时处理系统。如果开发人员没意识到这样的问题,很可能会代码设计成曝光数据等待点击数据进行关联。关联不上曝光数据的点击数据就很容易被一些简单的条件判断语句抛弃。
对于离线处理来说,消息都是批处理,不存在关联不上的情况。在Lambda架构下,即使实时部分数据处理存在一定丢失,但因为离线数据占绝对优势,所以对整体结果影响很小。即使当天的实时处理结果存在问题,也会在第二天被离线处理的正确结果进行覆盖。保证了最终结果正确。
Flink(Blink)的解法
先整理一下Lambda架构和Kappa架构的优缺点:
| 优点 | 缺点 |
Lambda | 1、架构简单 2、很好的结合了离线批处理和实时流处理的优点 4、稳定且实时计算成本可控 5、离线数据易于订正 | 1、实时、离线数据很难保持一致结果 2、需要维护两套系统 |
Kappa | 1、只需要维护实时处理模块 2、可以通过消息重放 3、无需离线实时数据合并 | 1、强依赖消息中间件缓存能力 2、实时数据处理时存在丢失数据可能。 |
