作者:吴叶磊
来源:http://aleiwu.com/post/aliyun-exporter-bp/
去年底我写了一个阿里云云监控的 Prometheus Exporter, 后续迭代的过程中有一些经验总结, 这篇文章就将它们串联起来做一个汇总, 讲讲为什么要写 Exporter 以及怎么写一个好用的 Exporter?
何为 Prometheus Exporter?
Prometheus 监控基于一个很简单的模型: 主动抓取目标的指标接口(HTTP 协议)获取监控指标, 再存储到本地或远端的时序数据库. Prometheus 对于指标接口有一套固定的格式要求, 格式大致如下:
http_requests_total{method="post",code="200"} 1027
http_requests_total{method="post",code="400"} 3
对于自己写的代码, 我们当然可以使用 Prometheus 的 SDK 暴露出上述格式的指标. 但对于大量现有服务, 系统甚至硬件, 它们并不会暴露 Prometheus 格式的指标. 比如说:
- Linux 的很多指标信息以文件形式记录在 /proc/ 下的各个目录中, 如 /proc/meminfo 里记录内存信息, /proc/stat 里记录 CPU 信息;
- Redis 的监控信息需要通过 INFO 命令获取;
- 路由器等硬件的监控信息需要通过 `SNMP** 协议获取;
要监控这些目标, 我们有两个办法, 一是改动目标系统的代码, 让它主动暴露 Prometheus 格式的指标, 当然, 对于上述几个场景这种办法完全是不现实的. 这时候就只能采用第二种办法:
- 编写一个代理服务, 将其它监控信息转化为 Prometheus 格式的指标
这个代理服务的基本运作方式, 可以用下面这张图来表示:
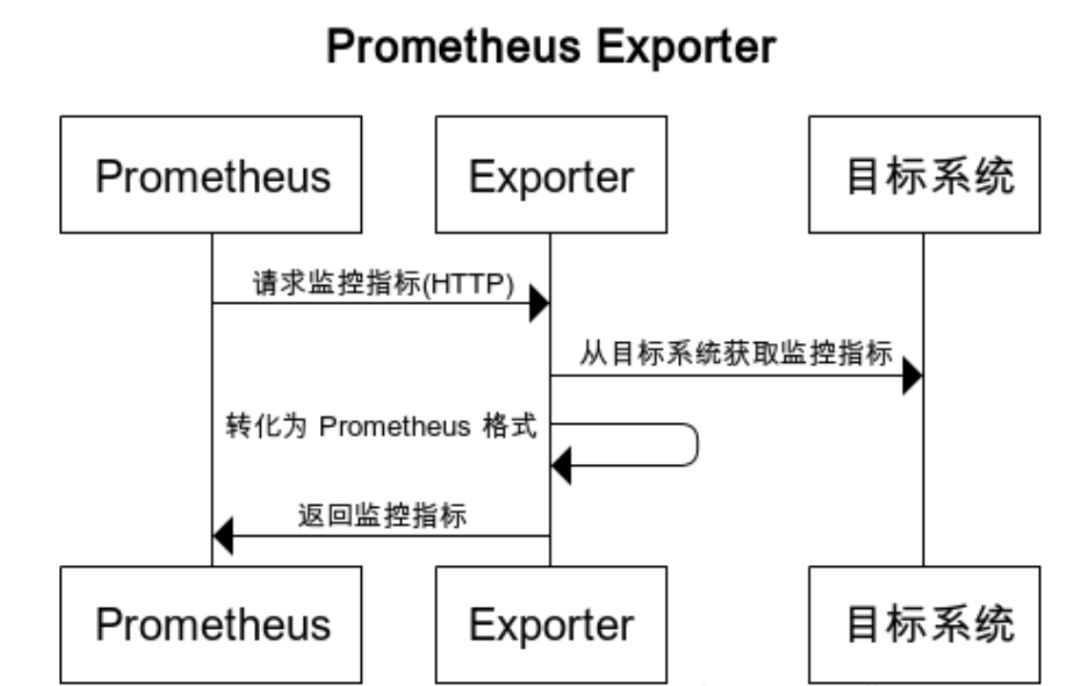
而这样的代理服务, 就称作 Prometheus Exporter, 对于上面那些常见的情形, 社区早就写好了成熟的 Exporter, 它们就是 node_exporter, redis_exporter 和 snmp_exporter.
为什么要写 Exporter?
嗯, 写 exporter 可以把监控信息接进 Prometheus, 那为什么非要接进 Prometheus 呢?
我们不妨以阿里云云监控为例, 看看接进 Prometheus 的好处都有啥:阿里云免费提供了一部分云监控服务, 但云监控的免费功能其实很有限, 没办法支持这些痛点场景:
- Adhoc TopN 查询: 比如”找到当前对公网带宽消耗最大的 10 台服务器”;
- 容量规划: 比如”分析过去一个月某类型服务的资源用量”;
- 高级报警: 比如”对比过去一周的指标值, 根据标准差进行报警”;
- 整合业务监控: 业务的监控信息存在于另一套监控系统中, 两套系统的看板, 警报都很难联动;
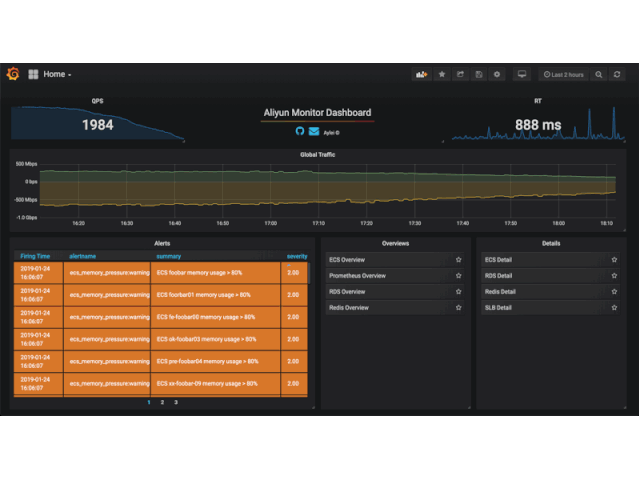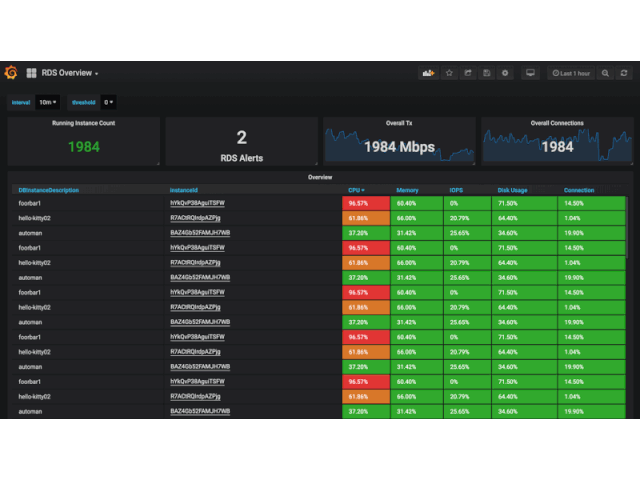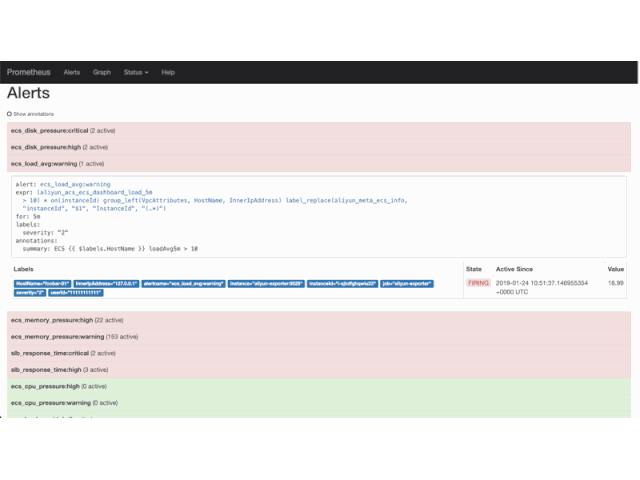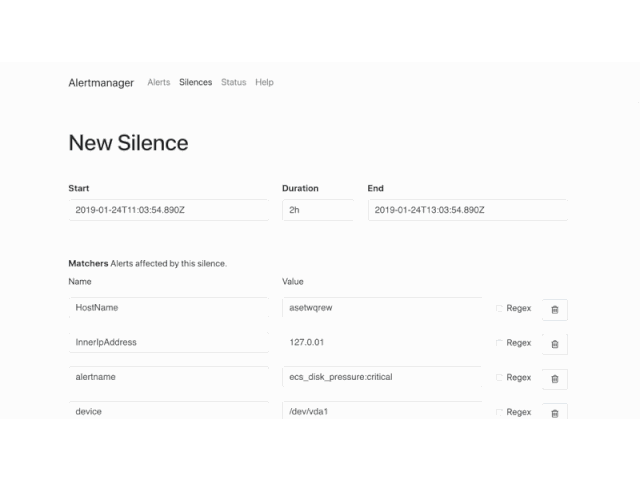
幸好, 云监控提供了获取监控信息的 API, 那么我们很自然地就能想到: 只要写一个阿里云云监控的 Exporter, 不就能将阿里云的监控信息整合到 Prometheus 体系当中了吗?集成到 Prometheus 监控之后, 借助 PromQL 强大的表达能力和 Alertmanager, Grafana 的强大生态, 我们不仅能实现所有监控信息的整合打通, 还能获得更丰富的报警选择和更强的看板能力. 下面就是一个对 RDS 进行 TopN 查询的例子:
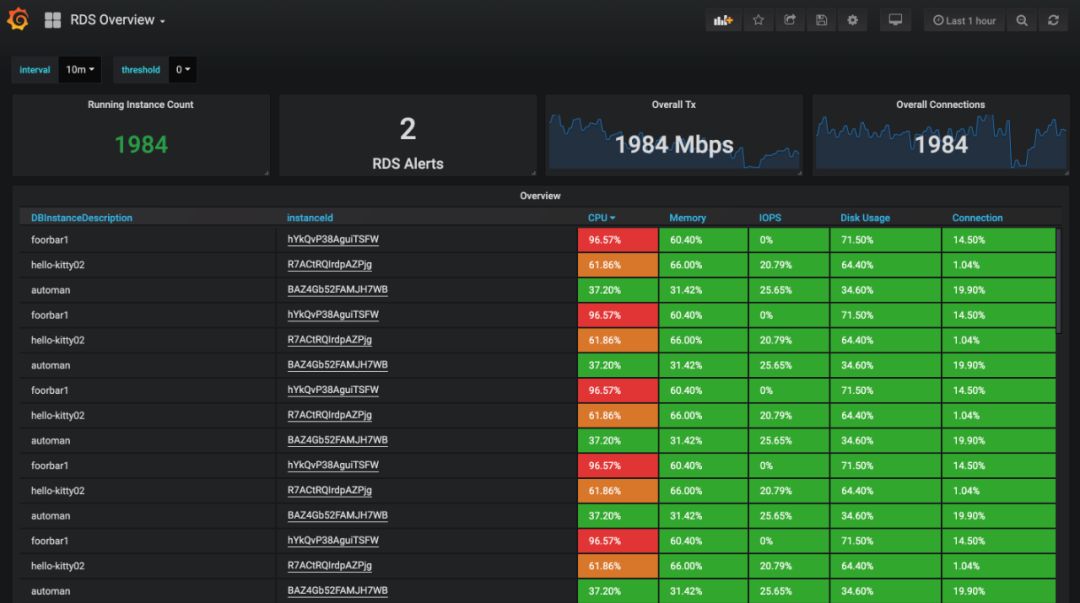
这个动机对于其它类型的 Exporter 也都是适用的: 当一个系统本身暴露了监控信息, 却又无法接入 Prometheus, 我们就可以考虑写一个 exporter 把它接进来了.
写一个好用的 Exporte
类似 “阿里云 Exporter” 这种形式的 Exporter 是非常好写的, 逻辑就是一句话:
- 写一个 Web 服务, 每当 Prometheus 请求我们这个服务问我们要指标的时候, 我们就请求云监控的 API 获得监控信息, 再转化为 Prometheus 的格式返回出去;
但这样写完之后仅仅是”能用”, 要做到”好用”, 还有诸多考量.
1、从文档开始
Prometheus 官方文档中 Writing Exporter 这篇写得非常全面, 假如你要写 exporter 推荐先通读一遍, 限于篇幅, 这里只概括一下:
- 为指标提供 HELP String (指标上的 # HELP 注释, 事实上这点大部分 exporter 都没做好)
下面几节中, 也会有和官方文档重复的部分, 但会略去理论性的部分(官方文档已经说的很好了), 着重讲实践例子.
2、可配置化
官方文档里讲了 Exporter 需要开箱即用, 但其实这只是基本需求, 在开箱即用的基础上, 一个良好的 Exporter 需要做到高度可配置化. 这是因为大部分 Exporter 暴露的指标中, 真正会用到的大概只有 20%, 冗余的 80% 指标不仅会消耗不必要的资源还会拖累整体的性能. 对于一般的 Exporter 而言, BP 是默认只提供必要的指标, 并且提供 extra 和 filter 配置, 允许用户配置额外的指标抓取和禁用一部分的默认指标. 而对于阿里云 Exporter 而言, 由于阿里云有数十种类型的资源(RDS, ECS, SLB…), 因此我们无法推测用户到底希望抓哪些监控信息, 因此只能全部交给用户配置. 当然, 项目还是提供了包含 SLB, RDS, ECS 和 Redis 的默认配置文件, 尽力做到开箱即用.
3、Info 指标
针对指标标签(Label), 我们考虑两点: “唯一性” 和 “可读性”:
“唯一性”: 对于指标, 我们应当只提供有”唯一性” 的(Label), 比如说我们暴露出 “ECS 的内存使用” 这个指标. 这时, “ECS ID” 这个标签就可以唯一区分所有的指标. 这时我们假如再加入 “IP”, “操作系统”, “名字” 这样的标签并不会增加额外的区分度, 反而会在某些状况下造成一些问题. 比方说某台 ECS 的名字变了, 那么在 Prometheus 内部就会重新记录一个时间序列, 造成额外的开销和部分 PromQL 计算的问题, 比如下面的示意图:
序列A {id="foo", name="旧名字"} ..................
序列B {id="foo", name="新名字"} .................
“可读性”: 上面的论断有一个例外, 那就是当标签涉及”可读性”时, 即使它不贡献额外的区分度, 也可以加上. 比如 “IP” 这样的标签, 假如我们只知道 ECS ID 而不知道 IP, 那么根本对不上号, 排查问题也会异常麻烦.可以看到, 唯一性和可读性之间其实有一些权衡, 那么有没有更好的办法呢?答案就是 Info 指标(Info Metric). 单独暴露一个指标, 用 label 来记录实例的”额外信息”, 比如:ecs_info{id="foo", name="DIO", os="linux", region="hangzhou", cpu="4", memory="16GB", ip="188.188.188.188"} 1这类指标的值习惯上永远为 1, 它们并记录实际的监控值, 仅仅记录 ecs 的一些额外信息. 而在使用的时候, 我们就可以通过 PromQL 的 “Join”(group_left) 语法将这些信息加入到最后的查询结果中:
aliyun_acs_rds_dashboard_MemoryUsage
* on (instanceId) group_left(DBInstanceDescription,DBInstanceStatus)
aliyun_meta_rds_info
阿里云 Exporter 就大量使用了 Info 指标这种模式来提供实例的详细信息, 最后的效果就是监控指标本身非常简单, 只需要一个 ID 标签, 而看板上的信息依然非常丰富:
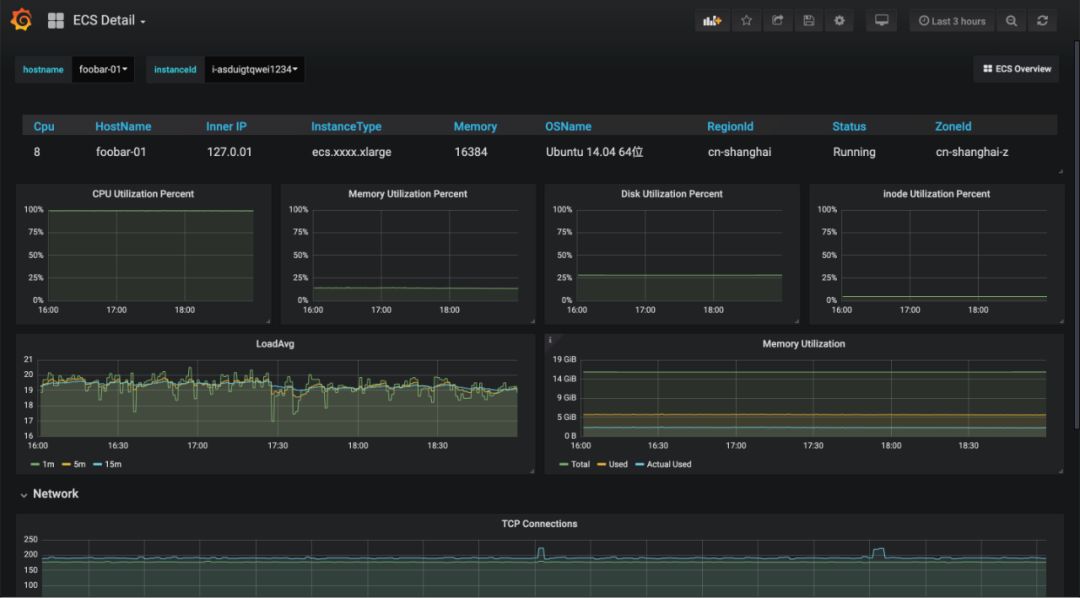
4、记录 Exporter 本身的信息
任何时候元监控(或者说自监控)都是首要的, 我们不可能依赖一个不被监控的系统去做监控. 因此了解怎么监控 exporter 并在编写时考虑到这点尤为重要.
首先, 所有的 Prometheus 抓取目标都有一个 up 指标用来表明这个抓取目标能否被成功抓取. 因此, 假如 exporter 挂掉或无法正常工作了, 我们是可以从相应的 up 指标立刻知道并报警的.但 up 成立的条件仅仅是指标接口返回 200 并且内容可以被解析, 这个粒度太粗了. 假设我们用 exporter 监控了好几个不同的模块, 其中有几个模块的指标无法正常返回了, 这时候 up 就帮不上忙了.因此一个 BP 就是针对各个子模块, 甚至于各类指标, 记录细粒度的 up 信息, 比如阿里云 exporter 就选择了为每类指标都记录 up 信息:
aliyun_acs_rds_dashboard_MemoryUsage{id="foo"} 1233456
aliyun_acs_rds_dashboard_MemoryUsage{id="bar"} 3215123
aliyun_acs_rds_dashboard_MemoryUsage_up 1
当 aliyun_acs_rds_dashboard_MemoryUsage_up 这个指标出现 0 的时候, 我们就能知道 aliyun rds 内存信息的抓取不正常, 需要报警出来人工介入处理了.另外, 阿里云的指标抓取 API 是有流控和每月配额的, 因此阿里云 exporter 里还记录了各种抓取请求的次数和响应时间的分布, 分别用于做用量的规划和基于响应时间的监控报警. 这也是”监控 exporter”本身的一个例子.
5、设计落地页
用过 node_exporter 的会知道, 当访问它的主页, 也就是根路径 / 时, 它会返回一个简单的页面, 这就是 exporter 的落地页(Landing Page).
落地页什么都可以放, 我认为最有价值的是放文档和帮助信息(或者放对应的链接). 而文档中最有价值的莫过于对于每个指标项的说明, 没有人理解的指标没有任何价值.
6、可选: 一键起监控
这一点超出了 exporter 本身的范畴, 但确确实实是 exporter “好用” 的一个极大助力. exporter 本身是无法单独使用的, 而现实情况是 Prometheus, Grafana, Alertmanager 再对接 Slack, 钉钉啥的, 这一套假如需要从头搭建, 还是有一定的门槛(用 k8s 的话至少得看一下 helm chart 吧), 甚至于有些时候想搭建监控的是全栈(gan)工程师, 作为全公司的独苗, 很可能更多的精力需要花在跟进前端的新技术上(不我没有黑前端…). 这时候, 一个一键拉起整套监控系统的命令诱惑力是非常大的.
要一键拉起整套监控栈, 首先 kubernetes 就不考虑了, 能无痛部署生产级 kubernetes 集群的大佬不会需要这样的命令. 这时候, 反倒凉透的 docker-compose 是一个很好的选择. 还是以阿里云 exporter 为例, 仓库提供的 docker-compose stack 里提供了 Prometheus, aliyun-exporter, Grafana(看板), Alertmanager(发警报), alertmanager-dingtalk-webhook(适配 alertmanager 的警报到钉钉机器人) 的一键部署并且警报规则和 Grafana 看板页一并配置完毕. 这么一来, 只要用户有一台装了 docker 的机器, 他就能在5分钟之内打开 Grafana 看到这些效果(还有钉钉警报…假如这位用户的服务器不太健康的话):
当然了, 想要稳固地部署这套架构, 还是需要多机做高可用或者直接扔到 k8s, swarm 这样的编排系统上. 但假如没有”一键部署”的存在, 很多对 Prometheus 生态不熟悉的开发者就会被拒之门外; 另外, 对于有经验的用户, “一键部署”也能帮助他们快速理解这个 exporter 的特性, 帮助他们判断是否需要启用这个组件.
结语

爆款云主机限时:https://www.aliyun.com/acts/limit-buy?userCode=d4m00na3
(en)



 简体中文
简体中文

